
Information Extraction from Paper sources
Introduction
Despite the majority of business being done digitally, many organisations still have a significant requirement for importing data from paper sources to their databases, often items such as invoices, receipts or purchase orders.
There are several tools for Optical Character Recognition (OCR) that make this work easier, however most require certain standards of text formatting to extract the information accurately and categories it correctly.
To tackle this issue, we set out to look for a tool that allows us to capture information from a paper source and came up with a service inside of SAP Cloud Platform called Document Information Extraction.
This service is powered by pre-trained machine learning algorithms which makes it possible to use as a plug and play solution for documents like invoices which are supported by the service.
To prove the viability of using Document Information Extraction we will test it on an example invoice to assess how accurately it is able to interpret the information on the document.
Set up
Before starting you need a SAP account with access to SAP Cloud Platform and to Document Information Extraction. This can be achieved by getting a free trial account if you’re not already a user. You will also need to install Postman as a REST client.
To begin with, we access the dev Space inside of the SAP cockpit where we are going to allocate the Document Information Extraction instance.
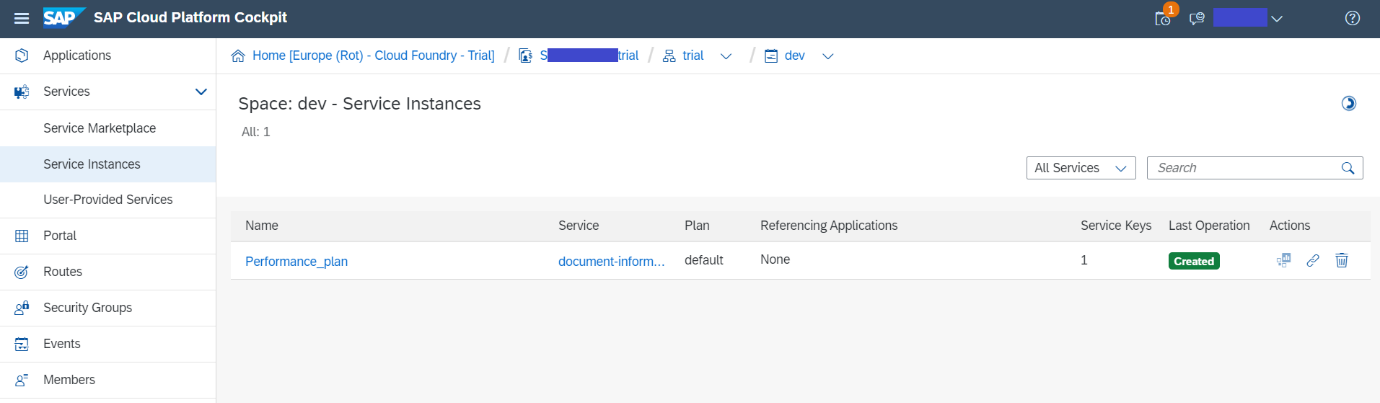
Once this initial set-up is complete, the next step is to create the service key. This will generate a JSON with the service key that includes the API endpoint url along with a username and password.
The URL given in the service key needs to be completed with “/document-information-extraction/v1” to access the API interface we will be handling in this proof of concept. The complete URL takes us to this page:
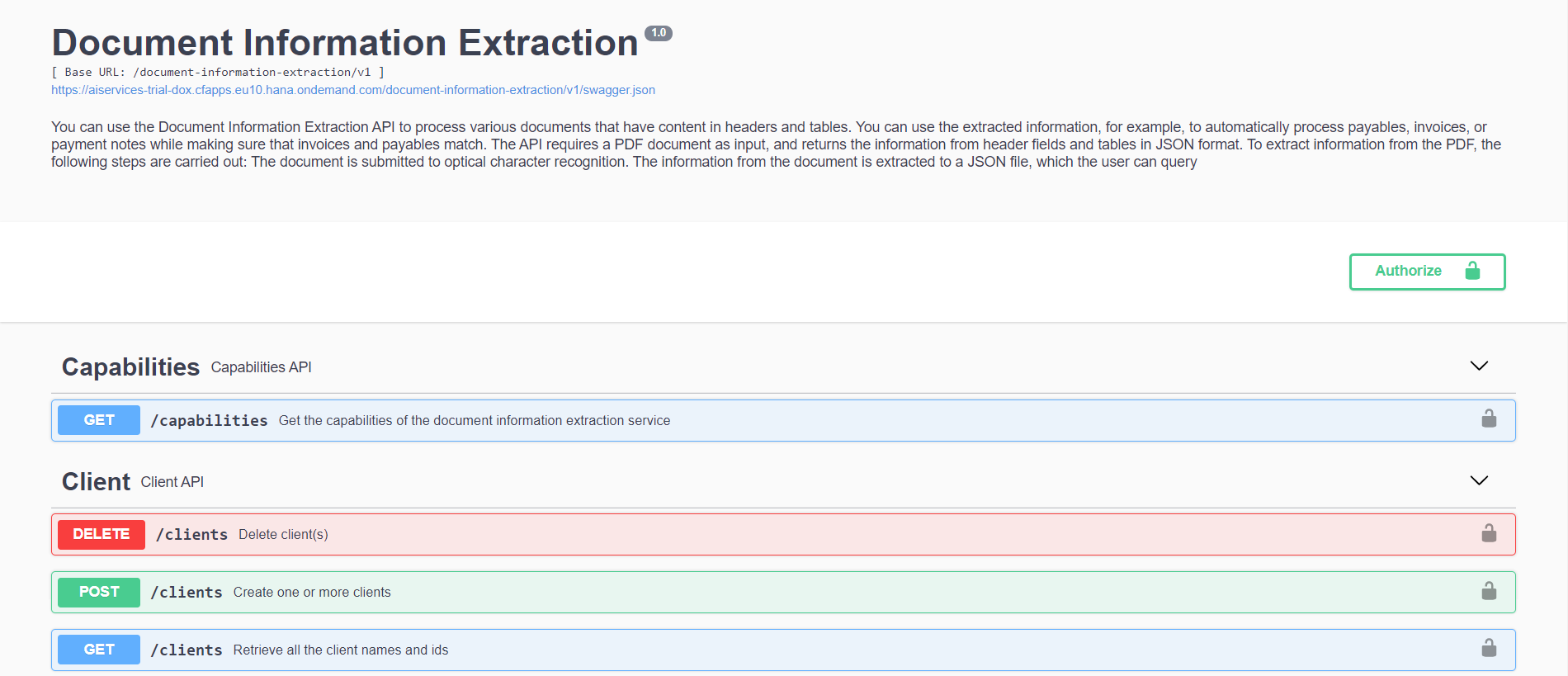
Here is where the magic happens. This is the interface we are going to use for the tool, but before we can transform the scanned image of an invoice into data we still need to fulfil a couple of steps. We need to generate an Authorization Bearer Token, which we are going to get using Postman with HTTP GET and then we are going to create the client to which we will submit the document for information extraction.
To get the bearer token we simply copy the URL value in the service key JSON on the uaa node and append “oauth/token?grant_type=client_credentials” to it. Inside the Authorization tab we are going to select “basic authorization” and use the credentials inside of the Service Key. If this is done correctly we should get a response containing the access token.
Now, to continue creating the client, we are going to click the Authorize button inside the API and in the “Value” field we are going to input the text “Bearer” followed by a space and the text on the access token node we received in the last step.
Then, we click on the POST option in the Client section and test the previously written code which should generate a ClientId and a ClientName. The code can be changed to modify ClientId and ClientName. After executing this code we should get a code 201 as the response confirming the client was correctly created.
After all these steps we are finally ready to test out the Document Information Extraction service.
To submit a document for processing we are going to click on the POST option.
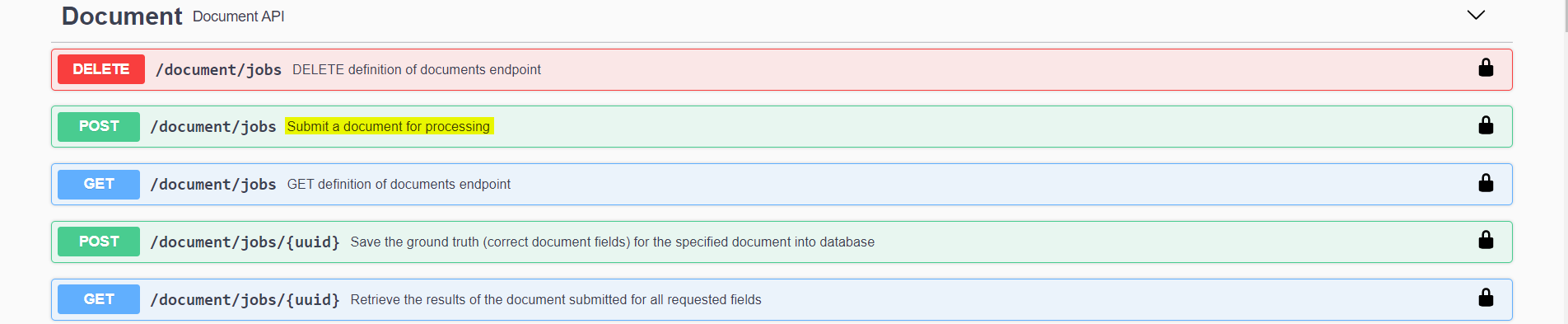
After clicking on Try it out we should get the option to upload a PDF document. For this proof of concept we are going to upload an invoice from an auto repair shop and see how accurate the service is at identifying the data.
Test Case
Invoice uploaded:
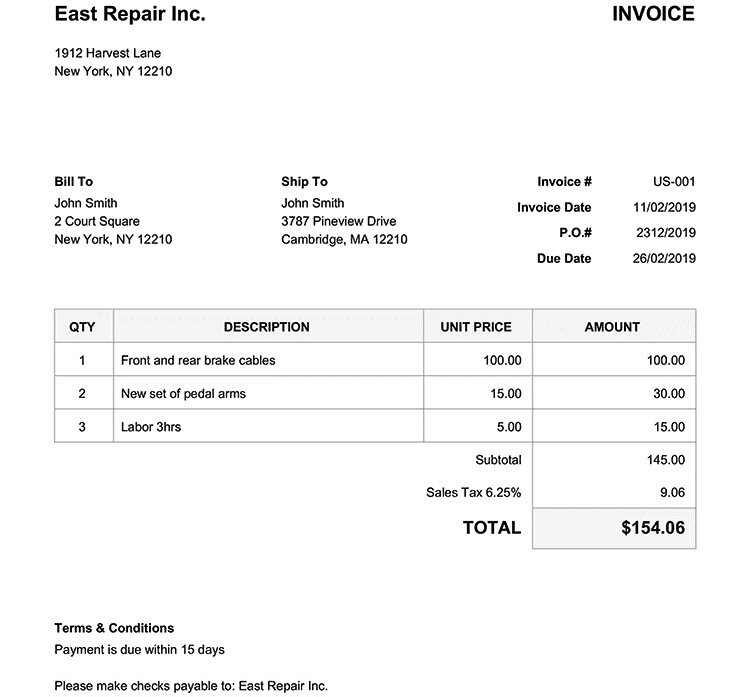
Submitting the documents will give us a response with an id for each document. To get the results we are going to use the GET option {uuid} and the ID we got from sending the documents, along with the clientId we are using, as below:
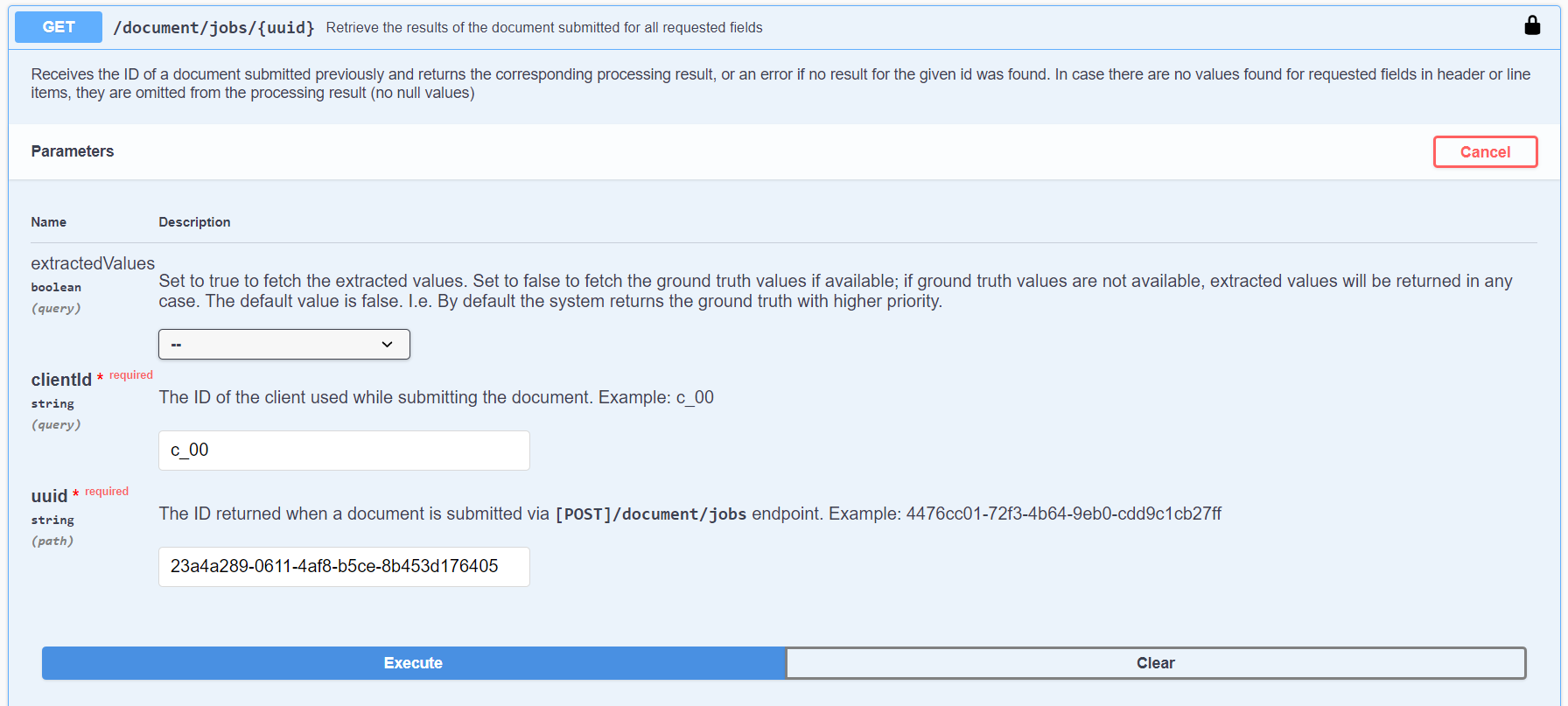
The response will contain a JSON with the information retrieved from the document. In our tests we retrieved the following data from the invoice:
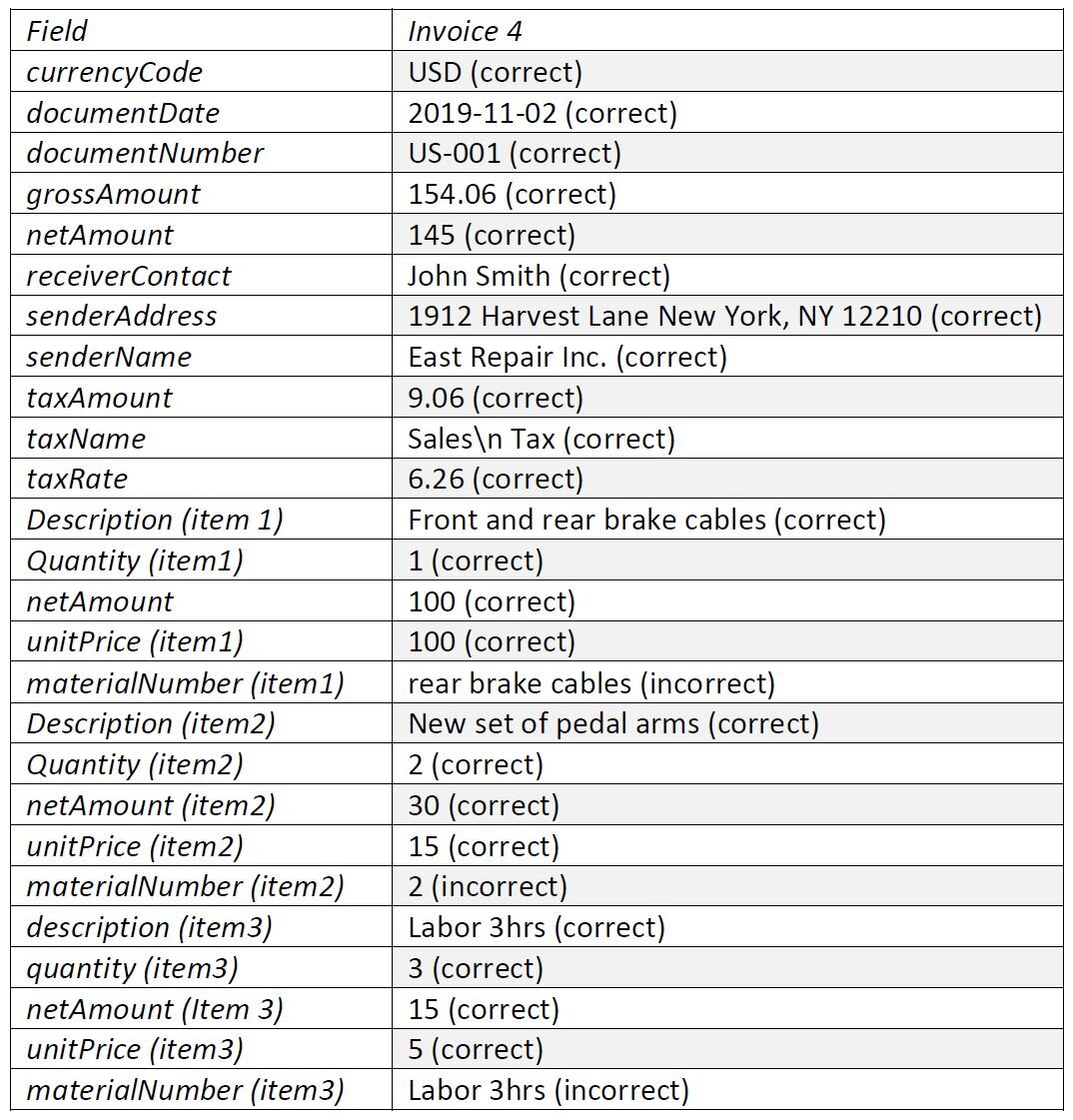
Conclusion
The Document Information Extraction tool on the SAP Cloud Platform is easy to set up and use and is highly accurate when analysing documents with formats supported by it.
It has the potential to save significant amounts of administration and processing time when compared to using an entirely manual process while maintaining high standards of accuracy.
For organisations which rely on transferring large amounts of data from physical copies to digital storage, using SAP Cloud Platform can introduce substantial cost savings.