
The new BI 4 offers a very powerful meta-layer capability: a single Universe can sit on top of several data-sources with great benefits offered by a real-time integration. At a first glance, you might think that existing Universes would need to be typed from scratch, but this article explains how to re-use an existing Universe to provide this highly scalable and expandable meta-layer.
The multi-source Universe
A multi-source Universe is now designed as a project with the following components:
- Connections
- Data Foundation
- Business Layer
These items can be created and configured separately, and then be connected one with another. The cycle of creating a new Universe is easy because the connections, data foundation and business layer can be created intuitively and always using the common SQL language, so no need to know native connection peculiarities. Once built, what happens behind the scenes is transparent to the end user and he/she will see that Business Objects will produce a query which takes pieces of information from different sources in real-time.
However, while the creation process is quite simple when generating a new Universe from scratch, it is not so straightforward if we are migrating from a legacy universe. Let’s see why.
UNV to UNX conversion process
In our experience, the three steps to be completed are the following:
- Legacy Universe (UNV) import: Using the standard migration process the legacy Universe can be inserted into the new BI4 platform. This can be done in a very short time and it has the following quick advantages:
- Migrated Web Intelligence reports will still sit on top of this legacy meta-layer.
- Live Office BI4, Crystal 2011 and other client tools can continue to perform as these are still using this format.
But we still cannot use platform modules like Explorer BI4 or Crystal Enterprise, or use the new security model or the new features advantages of the new Information Design platform, so the natural next step is to enable this.
- New Universe (UNX) conversion: From the Information Design tool we will click on File, “Convert .unv universe” and a new UNX universe is provided, with a project containing the three main items: Connection, Data Foundation and Business Layer. The advantages are the ones we previously stated, but there is one big disadvantage: The automatically generated Data Foundation is mono-source type, so the resulting Universe will not be scalable, and there is no easy way of turning a Data Foundation from mono to multi-source. Therefore this will need to be re-built. The process for re-building the Universe is explained simply in the following step.
- New Universe (UNX) multi-source conversion:
A new Data Foundation shall be created, following the steps stated below:
- Define connections
- Create new Data Foundation
- Copy and paste items to the new Data Foundation and/or re-type tables and joins using the standard SQL language.
Also the Business Layer needs changes, basically to be re-pointed to the new Data Foundation. The recommended steps are:
- Re-point the Business layer to the new Data Foundation
- The calls from the objects to the tables will need to be re-typed using the standard SQL language
A limitation in this stage is that the useful “View Associated Table” feature that showed the table lineage from a certain object has disappeared, so this might become quite a manual work. Opening the Universe Design tool in paral.lel with the Information Design tool to get the lineage might help here.
Once this is done, verify and export this new universe.
As a final step, the WebI reports can now be re-pointed to the new multi-source UNX so they can be enhanced with new alternative data.
Process summary
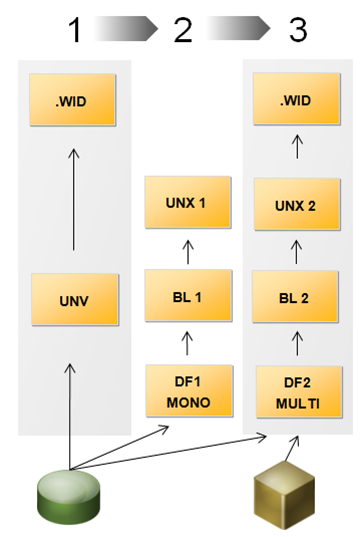
See in the following diagram a summary of the process:
- Step 1: Legacy Universe import
- Step 2: New Universe UNX conversion
- Step 3: New Universe UNX multi-source conversion
UNV to UNX conversion process summary
Conclusion
In the short term, in BI4 it should become a common practice to have 3 versions of the same universe:
- UNV: To preserve the legacy WebI reports and to use certain client tools like Crystal 2011 or Live Office.
- UNX mono-source: To use certain platform tools like Explorer or Crystal Enterprise and to have a higher level functionality.
- UNX multi-source: To use certain platform tools like Explorer or Crystal Enterprise, have a higher level functionality and be able to use several sources in one Universe.
Mid-term only this last multi-source version should remain.
Benefits
This Universe conversion method is time-efficient as it reuses all existing folders and objects, and shows tips for a better Universe re-creation.
The multi-source Universe gives superior benefits to the end user, providing a real-time integration and report design simplicity which will make their life easier. It also helps the meta-layer designers who will see their development time reduced with the help of the new design panel functionalities and a common standard language which is easier to understand. Project managers and architects can also consider the fact that they do not have to build a professional Data Warehouse for their projects, and with all this, IT managers will see a quick ROI and lower TCO for their investments.
If you have questions about this method or about the new Information Design Tool in SAP BI4, or if you want to share your experience or tips, please feel free to leave a comment!


























{kind=link}