On my previous blog post B-tree vs Bitmap indexes - Indexing Strategy for your Oracle Data Warehouse I answered two questions related to Indexing: Which kind of indexes can we use and on which tables/fields we should use them. As I promised at the end of my blog, now it´s time to answer the third question: what are the consequences of indexing in terms of time (query time, index build time) and storage?
Consequences in terms of time and storage
To tackle this topic I’ll use a test database with a very simplified star schema: 1 fact table for the General Ledger accounts balances and 4 dimensions - the date, the account, the currency and the branch (like in a bank).
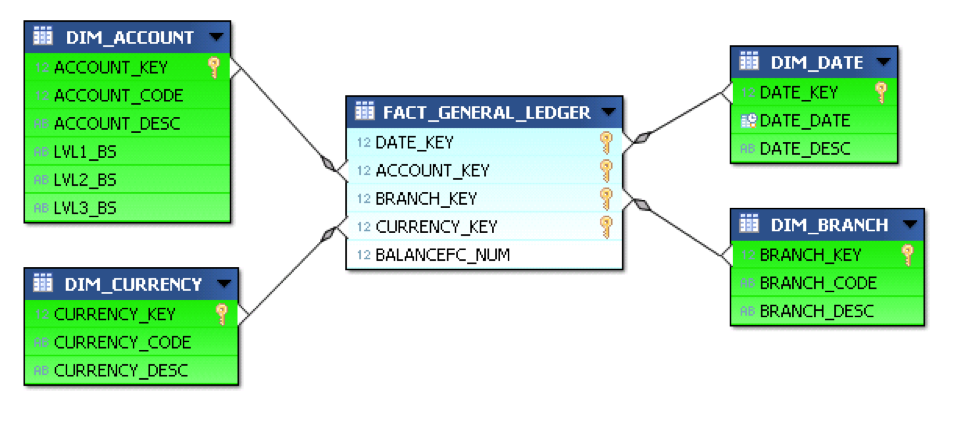
Simplified Star Schema
To give an idea of the table size, Fact_General_Ledger has 4,5 million rows, Dim_Date 14 000, Dim_Account 3 000, Dim_Branch and Dim_Currency less than 200.
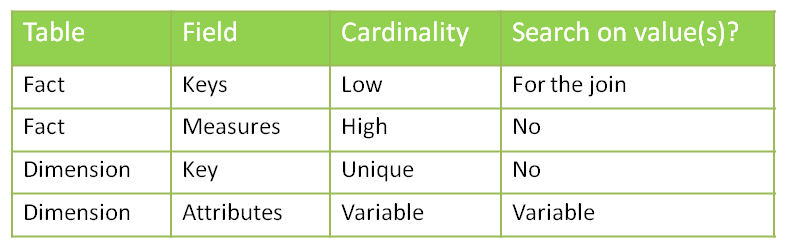
We’ll suppose here that the users could query the data with filter on the date, branch code, currency code, account code, and the 3 levels of the Balance Sheet hierarchy (DIM_ACCOUNT.LVLx_BS) . We assume that the descriptions are not used in filters, but in results only.
Here is the query we will use as a reference:
Select
d.date_date,
a.account_code,
b.branch_code,
c.currency_code,
f.balance_num
from fact_general_ledger f
join dim_account a on f.account_key = a.account_key
join dim_date d on f.date_key = d.date_key
join dim_branch b on f.branch_key = b.branch_key
join dim_currency c on f.currency_key = c.currency_key
where
a.lvl3_bs = 'Deposits With Banks' and
d.date_date = to_date('16/01/2012', 'DD/MM/YYYY') and
b.branch_code = 1 and
c.currency_code = 'QAR' -- I live in Qatar ;-)
So, what are the results in terms of time and storage?

Time and Storage Comparison
Some of the conclusions we can draw from this table are:
Using indexes pays off: queries are really faster (about 100 times), whatever the chosen index type is.
Concerning the query time, the index type doesn’t seem to really matter for tables which are not that big. It would probably change for a fact table with 10 billion rows. There seems however to be an advantage to bitmap indexes and especially bitmap join indexes (have a look at the explanation plan cost column).
Storage is clearly in favor of bitmap and bitmap join indexes
Index build time is clearly in favor of b-tree. I’ve not tested the index update time, but the theory says it’s much quicker for b-tree indexes as well.
Ok, I´m convinced to use Indexes. How do I create/maintain one?
The syntax for creating b-tree and bitmap indexes is similar:
Create Bitmap Index Index_Name ON Table_Name(FieldName)
In the case of b-tree indexes, simply remove the word “Bitmap” from the query above.
The syntax for bitmap join indexes is longer but still easy to understand:
create bitmap index ACCOUNT_CODE_BJ
on fact_general_ledger(dim_account.account_code)
from fact_general_ledger,dim_account
where fact_general_ledger.account_key = dim_account.account_key
Note that during your ETL, you’d better drop/disable your bitmap / bitmap join indexes, and re-create/rebuild them afterwards, rather than update them. It is supposed to be quicker (however I’ve not made any tests).
The difference between drop/re-create and disable/rebuild is that when you disable an index, the definition is kept. So you need a single line to rebuild it rather than many lines for the full creation. However the index build times will be similar.
To drop an index: “drop index INDEX_NAME”
To disable an index: “alter index INDEX_NAME unusable”
To rebuild an index: “alter index INDEX_NAME rebuild”
Conclusion
The conclusion is clear: USE INDEXES! When properly used, they can really boost query response times. Think about using them in your ETL as well: making lookups can be much faster with indexes.
If you’d like to go any further I can only recommend that you read the Oracle Data Warehousing Guide. To get it just look for it on the internet (and don’t forget to specify the version of your database – 10.2, 11.1, 11.2, etc.). It’s a quite interesting and complete document.