Managing ETL dependencies with SAP BusinessObjects Data Services (Part 2)
Are you satisfied with the way you currently manage the dependencies in your ETL? In part 1 of this article, I talked about the features I’m expecting from a dependency management system, and what are the main possibilities offered (directly or indirectly) by SAP Data Services. Now (part 2 of the article), I’m going to propose an architecture (structure and expected behavior) for a dependency management system inside Data Services. The implementation details will come in part 3, while a feedback on how it went “in real life” as well as possible improvements will come in part 4.
The proposed architecture
What I’m going to develop now is the following: an improvement of the “One job with all processes inside” architecture.
The main features of this architecture are:
- Management of multiple dependencies (one flow can depend on multiple processes)
- Graceful re-start is possible. Full ETL restart is also an option.
We should first create two tables, FLOW_DEPENDENCIES and FLOW_STATUS.
- The table FLOW_DEPENDENCIES has two columns FLOW_NAME and PREREQUISITE. It has one line for each prerequisite.
For the example below (logical flow dependencies in a job)...
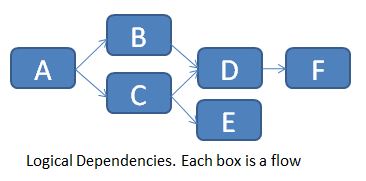
... we would populate the table FLOW_DEPENDENCIES as follows:

Of course you can’t directly implement these logical dependencies in Data Services, so you need to chain them one after the other.

The table is manually updated every time there is a new prerequisite. A flow without prerequisite doesn’t need any row in this table (see flow A for example).
The table FLOW_STATUS keeps track of the different flow statuses (Already run, Success, Failure, Missing Prerequisite) for each execution of the main job. The 3 columns are JOB_KEY (which contains a surrogate key for each new execution of the job), FLOW_NAME and STATUS.
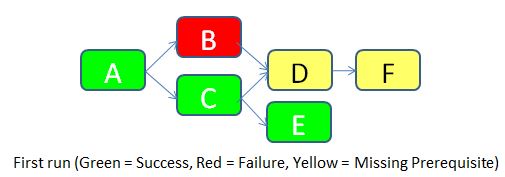
To make things clear, let’s imagine that we run the job for the first time (JOB_KEY = 1).
- Flow A doesn’t have any prerequisite, so it’s allowed to run. It is successful. A row with STATUS = Success is inserted in the FLOW_STATUS table.
- Flow B has a prerequisite according to the table FLOW_DEPENDENCIES (the flow A), so it checks the status of flow A in the same run. It turns out that the flow A was successful, so flow B is allowed to run. Unfortunately, it fails for an unknown reason. A row with STATUS = Failure is inserted in the FLOW_STATUS table.
- Flow C is allowed to run according to the same logic as for flow B. It runs successfully. A row with STATUS = Success is inserted in the FLOW_STATUS table.
- Flow D has two pre-requisites according to the table FLOW_DEPENDENCIES (flows B and C). It checks the status of both. As the flow B failed, the flow D is not allowed to run. A row with STATUS = Missing Prerequisite is inserted in the FLOW_STATUS table.
- Flow E is allowed to run according to the same logic flow B. It runs successfully. A row with STATUS = Success is inserted in the FLOW_STATUS table.
- Flow F has a prerequisite (Flow D). But as the status of flow D is “Missing Prerequisite”, flow F is also not allowed to run. A similar status is inserted in the flow status table.
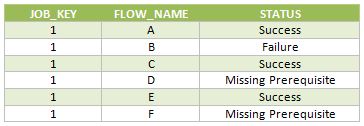
Below are the rows inserted in the FLOW_STATUS table during this job execution.
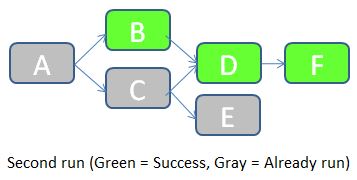
Once the error cause in the flow B has been corrected, we can re-run the job. JOB_KEY will be equal to 2, and we indicate to the job that it should check for statuses of the previous job (in which JOB_KEY = 1).
- The job starts by checking the status of the flow A in the table FLOW_STATUS with JOB_KEY = 1. As the status is equal to Success, the flow A doesn't need to be run in this job. A row with STATUS = “Already run” is inserted in the FLOW_STATUS table.
- Status of flow B with JOB_KEY = 1 is “Failure”. The flow B should accordingly be executed during this job. The job then checks the status of the prerequisite (the flow A) for JOB_KEY = 2. It turns out that the flow A was already run, so flow B is allowed to run. It runs successfully. A row with STATUS = Success is inserted in the FLOW_STATUS table.
- Remaining flows follow a similar logic.
Below are the rows inserted in the FLOW_STATUS table during this job execution.

As you can see, this solution manages the ETL dependencies, keeps trace of the load history, and allows easily a partial re-run of the ETL if a part of it failed. In the next part I’ll give you the details of the Data Services implementation: which scripts/flows/functions/etc. shall we use? How do we make this system easy to implement and maintain? Until then, I’m looking forward to your opinion on this proposed architecture. Does it look good? How would you improve it? Let me know with a comment below.